
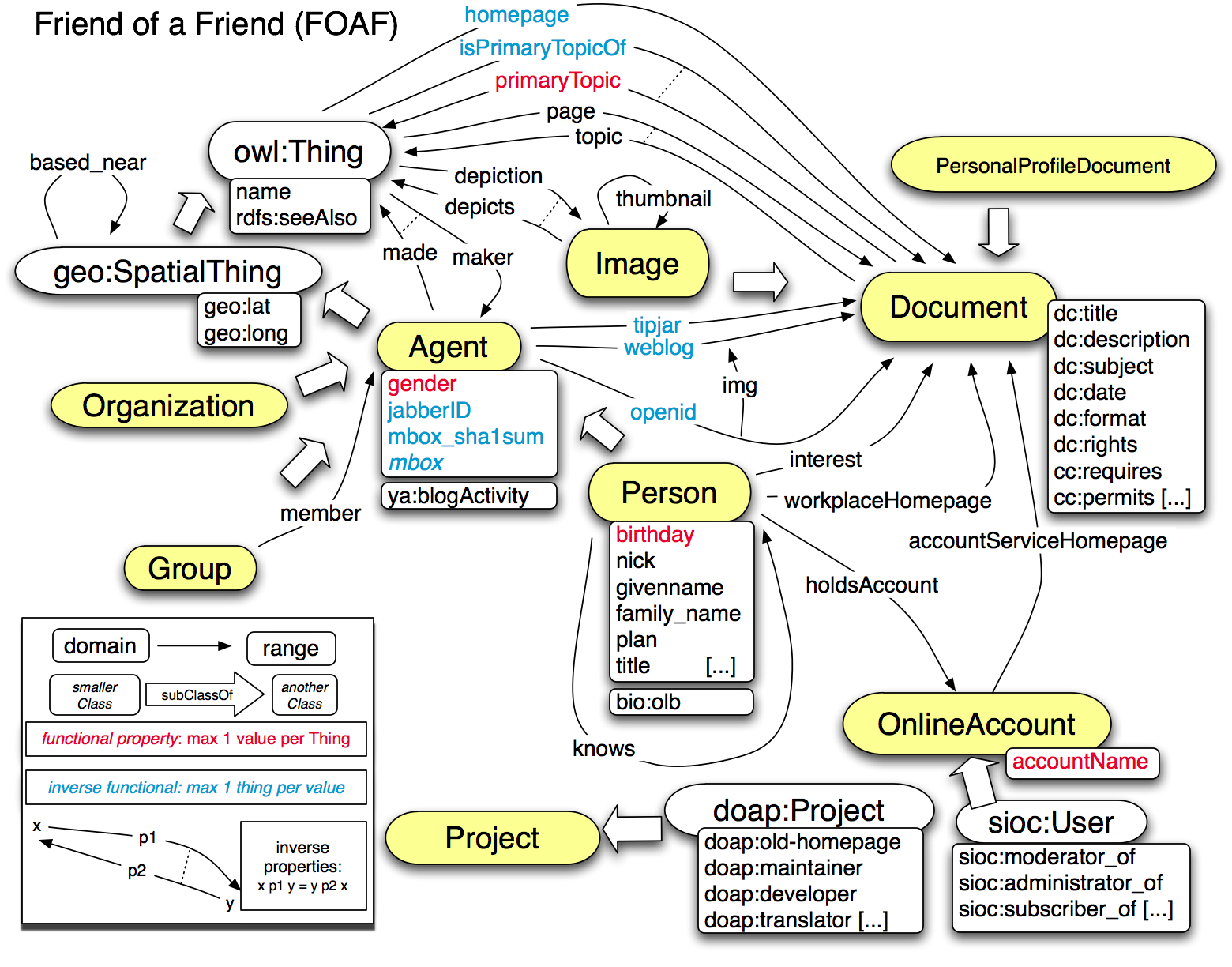
Como se puede ver en el ejemplo, o bien utilizando el prototipo, existen solo dos tipos de relaciones:
- La primera es una relación dirigida (con flecha), que une dos clases, para representar la propiedad sub-clase.
- La segunda relación permite unir una propiedad con una clase y es para indicar el rango de una propiedad.
El dominio de una propiedad esta dada por el contexto de orden sobre una clase, el cual se debe implementar con algún tipo de restricción visual (enmarcando clase con sus propiedades, por ejemplo). Además, se deben agregar restricciones de cardinalidad para las propiedades.
Una lista de características que debiera tener la versión 0.1 del editor es la siguiente:
- Permitir selección de múltiples elementos con draging options, operaciones de move y delete
- Eliminar clases y propiedades del diagrama
- Mostrar y ocultar propiedades y sus relaciones de rango
- Agrupar propiedades "dentro" de una clase
- Ingresar cardinalidad en relación de propiedades
- Exportar e Importar el diagrama
- Activar puntos sin conexión solo ante un MouseOver













{kind=link}